Explaining Policy Gradient methods in Reinforcement learning Part 1 : REINFORCE algorithm
Introduction
In the realm of artificial intelligence, equipping machines with the ability to learn and adapt in diverse environments is a central goal. Among the myriad of techniques developed, policy gradient methods emerge as a potent strategy within reinforcement learning (RL). These methods, grounded in mathematical theory and innovative algorithms, are widely employed across various domains, including robotics, gaming, and natural language processing (NLP).
Policy gradient methods originated in the early days of RL research, with significant advancements like the REINFORCE algorithm emerging in the 1990s. These methods diverge from traditional RL techniques by directly adjusting the policy — a strategy dictating an agent’s actions — based on the expected return, rather than estimating a value function to determine the best actions.
In robotics, policy gradient methods have enabled robots to master complex tasks such as manipulation and navigation within dynamic settings. In the gaming sphere, they have been instrumental in training autonomous agents for video games and refining strategies for board games like Go and chess, often surpassing human expertise.
Recently, policy gradient methods have also been applied in NLP to fine-tune pre-trained Large Language Models (LLMs), such as the GPT series. These models, initially trained via supervised or self-supervised learning, benefit from policy gradient methods for tasks like text generation, machine translation, and sentiment analysis, achieving unparalleled performance.
This article will delve into the inner workings of policy gradient methods, elucidating the mathematical intricacies of estimating the gradient of the objective function. We will introduce the REINFORCE algorithm, a foundational technique in policy gradient methods, known for its Monte Carlo approach to gradient estimation.
Vanilla Policy Gradient
In value-based methods, our objective was to estimate the action values to derive good policies. Policy Gradient methods focus directly on optimizing the policy with respect to the objective function, which is the expected discounted return.

Our goal is to maximize this objective function depending on θ. Naturally, we would use something like gradient ascent and take a step in the ascending direction.

To do so, we need to compute the gradient term to update the parameters θ.
First, let us express the trajectory and the corresponding reward as a whole instead of individual state-action pairs:

Now we can rewrite the objective function as follows:

Going back to the objective function we can write the gradient as follows:

We end up with an expectation of the gradient of the objective function in (10).
However, we still cannot evaluate it just yet because we do not know the term ρθ(τ).
Therefore, we need to find an alternative expression for it:
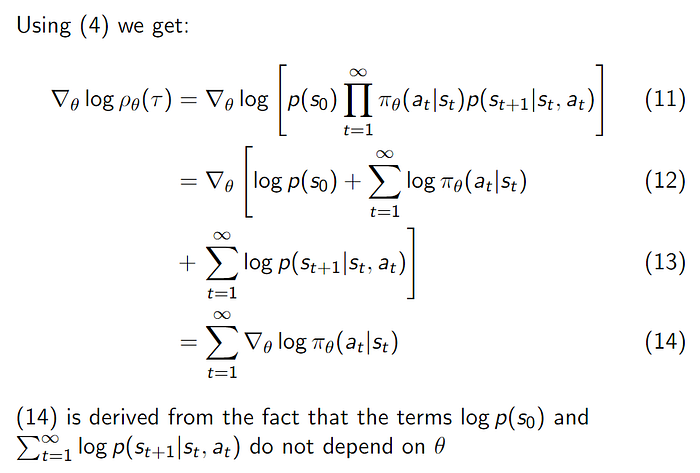
Now given a batch of N trajectories we can estimate the gradient as follows:
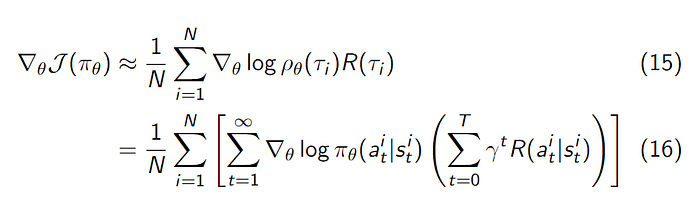
The gradient in essence aims to maximize the liklihood of trajectories with high total rewards and minimize that of those with low rewards.
REINFORCE
The REINFORCE algorithm is one of the earliest PG methods, and it is a key component to understand in order to build upon it and compe with bettet methods to tackle realistic problems:

The algorithm is bascially suggesting sampling trajectories from the environment using a initial policy then estimating the gradient and updating θ.
Because we use samples trajectories to obtain the gradient estimate for the policy update, make this an on-policy method. Therefor samples obtained under different policies cannot be used to improve the existing policy, and since it requires complete trajectories to do the update, this algorithm is a Monte Carlo method.
Problems with Policy Gradient Methods
PG method face multiple challenges :
The Randomness of the environment : This may lead to many different trajectories with significantly varying gradients
The length of the sample trajectories: varying lengths could result in very different sums for the log and reward terms
Sparse Rewards: Sparsity could be problemetic and cause convergence or performance issues
The size of N: could be not enough to capture the full distribution
These problems lead to the estimates of the gradient having high variance , which destablizes the learning. Thus to make the learning feasible we need some adjustments to reduce this variance. In the next parts we shall explore some of these tricks as well as other PG algorithms such as A2C/A3C and PPO algorithms.
